|
|
|
-- Copyright 2005 by
Kindly hosted at: |
|

|
|
A central aspect for programming languages are the implementative memory management concepts.
|
RStringBuffer sb = new StringBuffer("ACDK");
|
The variable 'sb' holds a reference of the instance of StringBuffer. An object can be destroyed, if there is no more variable that holds a refernce to it. Reference Counting is a performative possibililty to develop slim applications in memory use.
Example for Reference Counting:
RStringBuffer append(RString s)
{
RStringBuffer sb = new StringBuffer(); // RefCount = 1
{
RStringBuffer sb2 = sb; // RefCount = 2
sb2->append(s);
} // RefCount = 1
return sb; // RefCount = 2
} // RefCount = 1
void foo()
{
RString str = new String("Hallo"); // RefCount = 1
RStringBuffer sb = append(str); // str.RefCount = 2,
// sb.RefCount = 1
// str.RefCount = 1
} // str.RefCount = 0 => destroy String
// sb.RefCount = 0 => destroy StringBuffer
|
 Garbage Collecting
Garbage Collecting
Garbage Collecting is based on the fact that objects, which can not be referenced through static or
local variable objects are released. The disadvantage of Reference Counting is that in cyclic referenced
objects, the reference counter never goes to Null. Therefore, the whole data structure can not be
released. A garbage collector does not have this restriction.
Cyclic Reference:
class A {
public:
RObject other;
};
{
RA a1 = new A(); // a1->refCount = 1
RA a2 = new A(); // a1->refCount = 1
a1->other = a2; // a2->refCount = 2
a2->other = a1; // a1->refCount = 2
}
// a1->refCount = 1, a2->refCount = 1
|
The mechanism that is used for Garbage Collection in ACDK, is based on a two-step Mark/Sweep algorithm.
The main idea behind the Mark/Sweep algorithm is to find out if an object is directly or indirectly externally accessable.
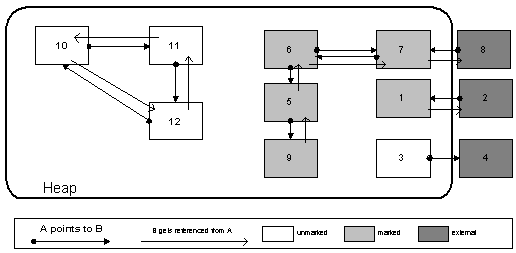
Example
1. Steps for marking the objects
- Object 1 referenced from an object outside of the set(external reference): Object gets marked.
- 2 is not referenced from an object: 2 is not marked.
- 5 gets referenced from 6. 6 is inside the set: continuing with 6
- 6 gets referenced from 7. 7 is inside the set: continuing with 7
- 7 gets referenced from 8. 8 is outside of the set: 7 gets marked. Back to 6.
- 6 gets referenced from a marked object (7) : 6 gets marked. Back to 5.
- 5 gets referenced from a marked object (6) : 5 gets marked.
- 9 gets referenced from 5 : 9 gets marked.
- For 10, 11 und 12: All objects only have internal, cyclic references. Objects do not get marked.
2. Step Removing non-external referenced objects
In Step 2, all objects that are not marked are released, since they are not accessable anymore. Memory areas
are typically devided into static data segment, stack and heap. An objects can be removed if it can't be
accessed directly or indirectly over the static data segment.A disadvantage of the garbage collecting mechanism is, that it has to know all allocated objects and deep searches for all references takes up too much time. A traditional garbage collector that works in the background, will also have to take the expense of synchronization over several threads into account.
The classical implementation of a garbage collector is predominantly found in the area of interpreter languages, since these have the necessary knowledge and control over objects in their runtime environment.
An intimate knowledge of the exact structure of stackframe, CPU register and adressing of platforms is necessary for compilated languages like C/C++.
A two-step mechanism is implementated for memory management in ACDK. A reference counting is used for standard structures. Garbage collection is only used for the removal of cyclic references.
ACDK compensates the disadvantages of the garbage collection by:
- Garbage Collecting is optional.
- Garbage Collecting is used as an 'Afterburner' for reference counting,
in order to not have so many objects in Heap.
- Heaps are managed via thread , so that synchronization of all threads is not necessary.
- ACDK can also be generated on on a stack.
- ACDK even allows alternative memory management mechanisms.
Stack Objects
Reference objects behave the same as Java objects. Therefore, accesses for invalid objects are handled with
a NullPointerException or synchronized methods are protected from concurrent accesses.Since this comfort costs runtime, it is possible for sychronized methods to allocate objects on a stack.
Unlike in C/C++, there is no more runtime overhead.
Difference between Heap and Stack objects:
// using Stack Object
StringBuffer sb(10); // NO cost for allocating with new
for (int i = 0; i < 10; i++) {
sb.add(i); /* NO cost for checking sb == Nil +
NO cost for dispatch virtual function +
NO cost for synchronizing in add
*/
}
-------------------------------------------------------------------------
void
addSomething(RStringBuffer sb) // Reference Object
{
sb->add("Save!"); /* cost for checking sb == Nil +
cost for dispatch virtual function +
NO cost for synchronizing in add */
}
StringBuffer sb(10);
addSomething(SR(StringBuffer, sb)); // convert StringBuffer to RStringBuffer
-------------------------------------------------------------------------
void
addSomething(StringBuffer& sb) // Stack Object
{
sb.add("Fast!"); /* NO cost for checking sb == Nil +
NO cost for dispatch virtual function +
NO cost for synchronizing in add */
}
RStringBuffer sb = getStringBufferFromElseWhere();
addSomething(*sb); // cost for checking sb == Nil
|
User-Heaps
Further user defined heaps can be instatiated for the usage of memory strategies.The following strategies are possible:
- Bulk memory. Fast pre-allocated memory, which is released as a whole after the calculation. Objects
are finalized, yet not de-allocated.
- Realtime memory. A Bulk Memory can be used for implementating realtime capabiltiy for processes.
- Shared Memory. For an easy Interprocess communication. Synchronization is managed over Mutex objects.
- Memory Mapped Files. For easy mapping of data structures within files in a memory structures.
- ROM. Mapping of objects within a Read Only Memory.
- Pooling Cache. Pooling Cache is used for having a high performance, while using many objects that are
formed the same. Therefore, released objects are only finalized and not de-allocated and can be re-used
for the next request.